

Cracking the code coverage myth
Why 100% code coverage doesn't guarantee bulletproof code


Writing software tests is one of those activities that can dramatically increase its robustness and reliability, allowing developers to correct and refactor code knowing that nothing has been damaged, however, test suites are made of code as well, written by humans and subject to bugs and incompleteness.
Code coverage comes to our aid, but it can also be harmful.
What is the code coverage?
Let's start with the definition of Code coverage.
Code coverage is a metric that measures the extent to which the source code of a software program is tested by a test suite.
It measures the percentage of code lines executed during the testing process.
The purpose of code coverage analysis is to determine the effectiveness of the testing efforts by identifying areas of code that have been inadequately tested.
Thanks ChatGpt for this definition.
Giving a basic example, this is what happens for coverage calculation.

Nothing more than this. Simple, right?
This applies to conditional statements as well.
function myFunction(value) {
console.log("I was here"); // COVERAGE OK
switch (value) {
case 1:
console.log("It is 1"); // COVERAGE OK
break;
case 2:
console.log("It is 2"); // NO COVERAGE
break;
case 3:
console.log("It is 3"); // NO COVERAGE
return false; // NO COVERAGE
break;
}
return true; // COVERAGE OK
}
// Test
myFunction(1);
There are three terms when we talk of code coverage:
hit: the line of code has been executed.
partial: the line of code has been executed, but there are remaining branches that were not executed (for example an if-else statement).
miss: the line of code has NOT been executed.
These terms are needed to calculate the code coverage:
Coverage is the ratio of
hits / (sum of hit + partial + miss). A code base that has 5 lines executed by tests out of 12 total lines will receive a coverage ratio of41%(rounding down).
It quantifies how thoroughly our tests "exercise" our codebase and it's a valuable metric because it highlights untested or under-tested parts of your code, hence 100% code coverage means that every single line of code is executed by at least 1 test function.
A warm, soft blanket during a blizzard
PASS app/calculator.test.js
✓ add function (1 ms)
---------------|---------|----------|---------|---------|-------------------
File | % Stmts | % Branch | % Funcs | % Lines | Uncovered Line #s
---------------|---------|----------|---------|---------|-------------------
All files | 100 | 100 | 100 | 100 |
calculator.js | 100 | 100 | 100 | 100 |
---------------|---------|----------|---------|---------|-------------------
Test Suites: 1 passed, 1 total
Tests: 1 passed, 1 total
Snapshots: 0 total
Time: 0.397 s, estimated 1 s
Wow, it appears that the code is fully tested!
Code coverage can be comforting and can strengthen the confirmation bias that our code works and is robust when we are just chasing the goal of having the "green light", a seal of approval.
Reality? Code coverage is nothing when we talk about quality and it leads us to trust ourselves the code more than we should. And we're going to prove it!
Some testing
The roadmap:
Setup a javascript project with jest
Write a function to test (very simple)
Write a test suite that reaches 100% coverage
Write a test suite that doesn't
# Initialize project
> npm init
package name: (dingdongbug) codecoverage_example
version: (1.0.0)
description: Example project for code coverage
entry point: (index.js)
test command: jest
git repository:
keywords:
author:
license: (ISC)
{
"name": "codecoverage_example",
"version": "1.0.0",
"description": "Example project for code coverage",
"main": "index.js",
"scripts": {
"test": "jest"
},
"author": "",
"license": "ISC"
}
# Install jest for testing
> npm install --save-dev jest
added 291 packages, and audited 292 packages in 31s
31 packages are looking for funding
run `npm fund` for details
found 0 vulnerabilities
The folder structure should look as follows.
> tree -L 1
.
├── node_modules
├── package-lock.json
└── package.json
2 directories, 2 files
Start coding
We are going to update the index.js adding our function to test.
function processInput(input) {
let output = input.toUpperCase();
let longString = false;
if (output.length > 5) {
output += '_longString';
longString = true;
}
return {
text: output,
isLong: longString
};
}
module.exports = processInput;
That's a very simple (and useless) function that just turns our string uppercase and finally adds a suffix if the text is longer than 5 characters.
It returns an object with the resulting string and a boolean flag indicating if the string was long enough for a suffix.
Let's keep going with test classes, starting from what will be called sweetLie.test.js.
const processInput = require('./index.js');
test('pass a short string', () => {
let result = processInput('Short');
expect(result).not.toBe(null);
});
test('pass a long string', () => {
let result = processInput('Longer string');
expect(result).not.toBe(null);
});
This test suite runs two tests:
The first one invokes the
processInputfunction with a short string and checks the result is not nullThe second one invokes the
processInputfunction with a string longer than 5 and checks the result is not null
Then we move on to the second suite: bitterTruth.test.js.
const processInput = require('./index.js');
test('pass a short string', () => {
const input = 'Short';
let result = processInput(input);
expect(result).not.toBe(null);
expect(result.isLong).toBe(false);
expect(result.text).toBe(input.toUpperCase());
});
test('pass an empty string', () => {
const input = '';
let result = processInput(input);
expect(result).not.toBe(null);
expect(result.isLong).toBe(false);
expect(result.text).toBe(input);
});
test('pass null', () => {
expect(() => {
processInput(null);
}).toThrow();
});
It is immediately evident how this suite goes deeper into testing.
The first test invokes the
processInputfunction with a short string then checks:The result is not null.
The result object has the property
isLongequal to false.The transformed text is uppercase.
The second test invokes the
processInputfunction with an empty string then checks:The result is not null.
The result object has the property
isLongequal to false.The transformed text is equal to the initial input.
The last test invokes the
processInputfunction with a null string checking that an error is thrown.
Coverage
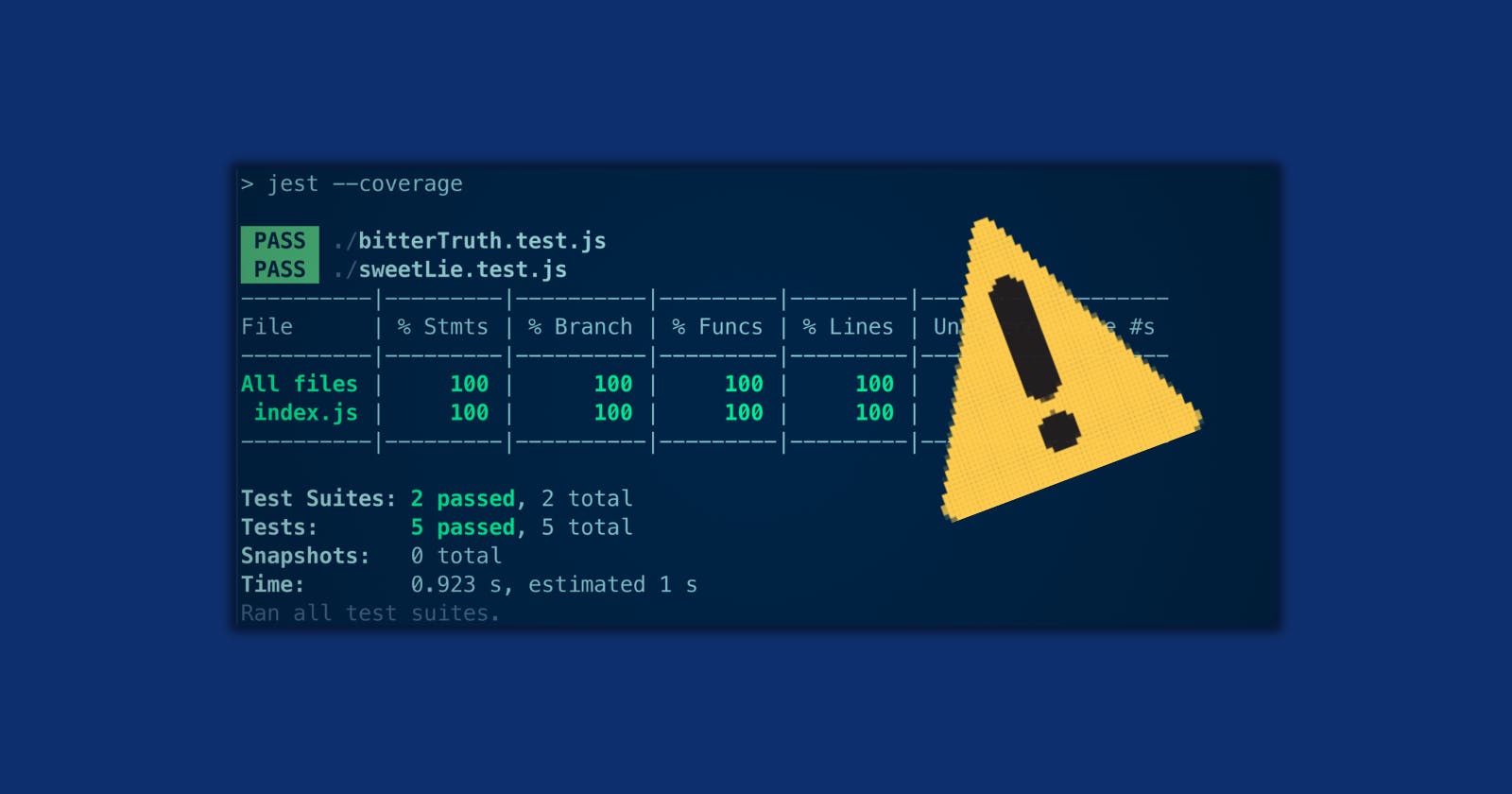
Now let's try running our sweet lie suite with the coverage flag.
> npm test -- sweetLie.test --coverage
> codecoverage_example@1.0.0 test
> jest --coverage
PASS ./sweetLie.test.js
✓ pass a short string (4 ms)
✓ pass a long string (4 ms)
----------|---------|----------|---------|---------|-------------------
File | % Stmts | % Branch | % Funcs | % Lines | Uncovered Line #s
----------|---------|----------|---------|---------|-------------------
All files | 100 | 100 | 100 | 100 |
index.js | 100 | 100 | 100 | 100 |
----------|---------|----------|---------|---------|-------------------
Test Suites: 1 passed, 1 total
Tests: 2 passed, 2 total
Snapshots: 0 total
Time: 1.168 s
Ran all test suites.
Yuppie 🎉 All tests passed and 100% coverage! No missing statements, branches, functions or lines, not at all.
This is great, you will probably receive compliments and a pat on the back.
You could say: "Yes, but during the code review someone will stop me and ask me to test further" and I hope so, but it doesn't always go like this, or you could inherit a project with these tests, trusting what you see in the coverage report.
We can tell ourselves so many fairy tales, but this unfortunately remains a real case that can occur, if only because of the rush to release the product.

What if we run the bitter truth? Let's see.
> npm test -- bitterTruth --coverage
> codecoverage_example@1.0.0 test
> jest bitterTruth --coverage
PASS ./bitterTruth.test.js
✓ pass a short string (5 ms)
✓ pass an empty string (1 ms)
✓ pass null (14 ms)
----------|---------|----------|---------|---------|-------------------
File | % Stmts | % Branch | % Funcs | % Lines | Uncovered Line #s
----------|---------|----------|---------|---------|-------------------
All files | 71.42 | 50 | 100 | 71.42 |
index.js | 71.42 | 50 | 100 | 71.42 | 5-6
----------|---------|----------|---------|---------|-------------------
Test Suites: 1 passed, 1 total
Tests: 3 passed, 3 total
Snapshots: 0 total
Time: 2.262 s
Ran all test suites.
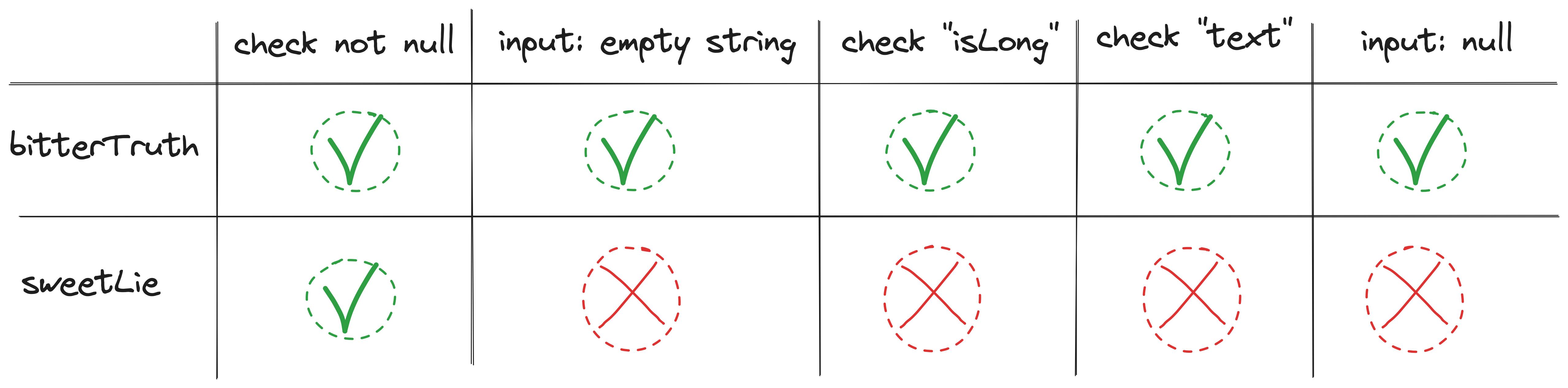
Apparently, the results are not so good: 50% of branches, 71% of statements which is lower than the 80% which is usually recommended.
The truth is that we built a test suite which is more robust and valuable than the previous one, even if our coverage is lower, because we are testing some edge cases and checking the values inside the result object.
Conclusions
Should I ignore code coverage?

No, code coverage is a tool like many others and is not the problem itself, what is actually problematic is how much trust we place in it because we want to satisfy our thirst for safety.
Code coverage offers simple but very important information: what's not been tested at all.
The focus of good test suites should always be on the expected behaviour, not on lines of code, however knowing that a block of code is never reached by tests helps us to be more aware that it might lead to unexpected results.
As we have seen, while high code coverage demonstrates that a significant portion of the code has been tested, it does not guarantee the effectiveness or reliability of those tests.
Well-written tests, tailored to specific functionalities and edge cases, are instrumental in ensuring that a project is robust and able to withstand real-world scenarios.